基于Claude Code学Agent
Claude Code是怎么工作的
让你给claude code一个任务的时候,它会跑一个循环:
- 收集上下文
- 采取行动
- 验证结果 直到完成任务为止 ,当然,在这个过程中你可以随时打断它。 这个过程有一个高级点的名称,叫做 agentic loop.
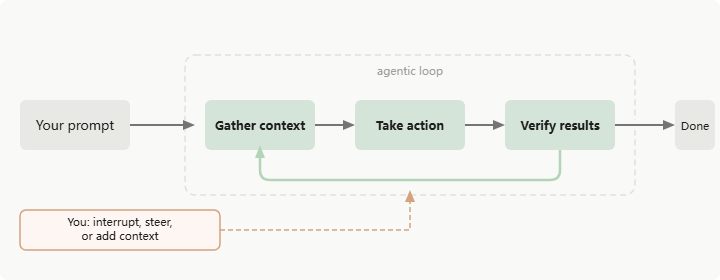
agentic loop里面由两个组件驱动:推理模型和行动需要的工具。
Subagent
Claude Code的subagent是个很好用的功能,它解决了agent工作中的大难题:长上下文管理。
大家都知道agent运行久了,上下文挤爆了模型窗口之后,agent的工作质量就会急剧下降。 subagent 有一个很大的点就是他有独立的上下文窗口,在工作中不需要占用主agent的空间,只需要在运行后将结果返回给主agent。
另外,每个subagent还可以有:
- 自定义的系统提示词
- 独立的工具访问权限,你可以限制subagent可选的工具
- 可以将
也就是subagent能够独立完成自己的目标。
claude code内置了几个subagents,会在适当的时候自动被调用起来。
- explore : 一个快速的、只读的代理,针对搜索和分析代码库进行了优化。
- plan: 在 plan mode 期间用于在呈现计划之前收集上下文的研究代理。
- general-purpose: 一个能够处理复杂、多步骤任务的代理,这些任务需要探索和操作。
subagent的类型
subagents其实也是带有 yaml 格式的md文件(和skills有点类似),不同的项目可能会把他们放在不同的位置的,
例如,放在电脑根目录下的 ~/.claude/agents/ 是全局级别的subagent,所有项目都可以用。
放在项目文件夹下的 : .claude/agents/, 就仅限于该代码库下使用。
还有CLI 定义的 subagents , 在启动 Claude Code 时作为 JSON 传递。它们仅存在于该会话中,不会保存到磁盘,使其对快速测试或自动化脚本很有用:
claude --agents '{
"code-reviewer": {
"description": "Expert code reviewer. Use proactively after code changes.",
"prompt": "You are a senior code reviewer. Focus on code quality, security, and best practices.",
"tools": ["Read", "Grep", "Glob", "Bash"],
"model": "sonnet"
}
}'如何创建subagent
Subagent 文件使用 YAML frontmatter 进行配置,后跟 Markdown 中的系统提示:
例如一个代码评审的subagent 示例如下 :
---
name: code-reviewer
description: Reviews code for quality and best practices
tools: Read, Glob, Grep
model: sonnet
---
You are a code reviewer. When invoked, analyze the code and provide
specific, actionable feedback on quality, security, and best practices.从这里可以看出,subagent还可以选择其他模型,说明一些简单的任务交给subagent后,也可以选择比较便宜或者更加专注的模型来完成任务。
https://code.claude.com/docs/zh-CN/sub-agents#%E5%86%85%E7%BD%AE-subagents
Claude Code的插件
插件Plugin是Claude Code最高级别的拓展,可以将自定义命令,subagent,mcp,hook,skills都打包在一起,方便团队多用户中的共享协作和分发。
简单来说,插件就是将claude code拓展能力的工具箱打包在一起,使用了插件就不需要每个项目都重复配置了。
多Agent架构
在构建复杂的AI Workflow的时候,依赖单一大模型或者单一Agent逐渐难以完成人类要求的任务,尤其是上下文一长,AI就容易失忆,任务质量骤减
多Agent协作模式通过将系统构建为适合不同Agent协作集合来解决这个问题。
何时使用多Agent
并非所有任务都需要多Agent,以下是判断依据
- 当任务可以拆分为独立子任务,子任务之间依赖越少,多Agent的加速效果越明显
- 需要不同专业领域: 当任务同时设计写代码,数据分析,爬网页,生成总结等不同技能组合,专门的agent在输出的品质优于通用代理
- 成本: 不是每个子任务都用最贵的模型,路由决策可以gpt4omini,深度推理用gpt5.3 ,这种混合模型策略是多agent独特的成本优势
多Agent协作模式
多Agent协作模式中可以采取各种形式,如:
- 顺序交接: 一个Agent完成任务并将其输出传递给下一个Agent以进行工作流的下一步
- 并行处理: 多个Agent同时处理问题的不同部分,最后将结果组合
- 辩论和共识: 多Agent协作,具有不同观点和信息来源的Agent进行讨论来评估选项,最终达成共识
- 层次结构: 管理者Agent可能根据其工具访问或插件能力动态将任务委托给Agent,以综合其结果,每个Agent还可以处理相关的工具
举例:OpenClaw就提供了三种层次的多Agent协作机制,从简单到复杂依次为: Sub Agent,AgentTeams和AgentToAgent(跨代理通讯)。
三种机制的定位 SubAgent 子代理:一对多的主从关系。主代理(Parent Agent)將子任務委派給子代理(SubAgent)执行,子代理完成后返回结果 Agent Teams 团队:多对多的平等或者阶层协作,多個代理被組成团队,通过共享上下文和协调者角色共同完成复杂任务。适合需要及时沟通与动态分工的场景。 AgentToAgent 跨代理通訊:跨实例、跨环境的代理协作。 当agent分布在不同机器,不同openclaw gateway实例上时,透过结构化讯息定义实现远端协作
上下文工程
什么是上下文窗口
上下文窗口Context Window是LLM单次能够处理的最大token长度,需要同时容纳输入token和输出token,这意味着在实际应用中,需要谨慎规划输入内容的规模,为输出留出足够空间。
例如,一个 8K 窗口的模型:
- 如果输入占用 6K Token
- 则输出最多只剩 2K Token 的空间
上下文的限制来自多个层面:
- 位置编码:Transformer使用位置编码让模型感知token的位置,传统的绝对位置编码难以泛化到训练时未见过的长度
- KV缓存: 在生成过程中,模型需要缓存之前所有的Token的key和value向量,KV缓存大小和上下文长度成正比————一个70B参数模型的128K上下文可能需要 10GB显存
- 注意力计算:自注意力的复杂度使得超长上下文的计算成本极高。
上下文工程
上下文工程强调对模型信息环境的构建————既要包含任务必须的全部关键信息,又需要避免冗余内容导致的注意力分散和成本增加
上下文工程由输入、记忆、输出三大部分组成, 输入包括系统提示词,外部知识,工具定义,环境感知和用户输入。 记忆分为长期记忆和短期记忆,用于存储和召回历史信息。 输出则包括工具执行的结果和模型生成的结构化内容。 这些组件共同协作,构建一个丰富的上下文环境,以支持llm完成复杂任务
假设是一个传统RAG系统,通常是检索-->生成,在agent系统里,系统必须具备规划和任务分解能力。
Agent的动作可能包括:
- 信息流控制: 决定何时检索,何时生成
- 策略自适应: 支持失败重试,源切换,方法切换
- 上下文治理: 清理冗余和冲突信息
- 多步任务规划: 跨工具,跨数据源操作
构建系统上下文是一个工程,它通常包括上下文检索和生成、上下文处理和上下文管理三个部分
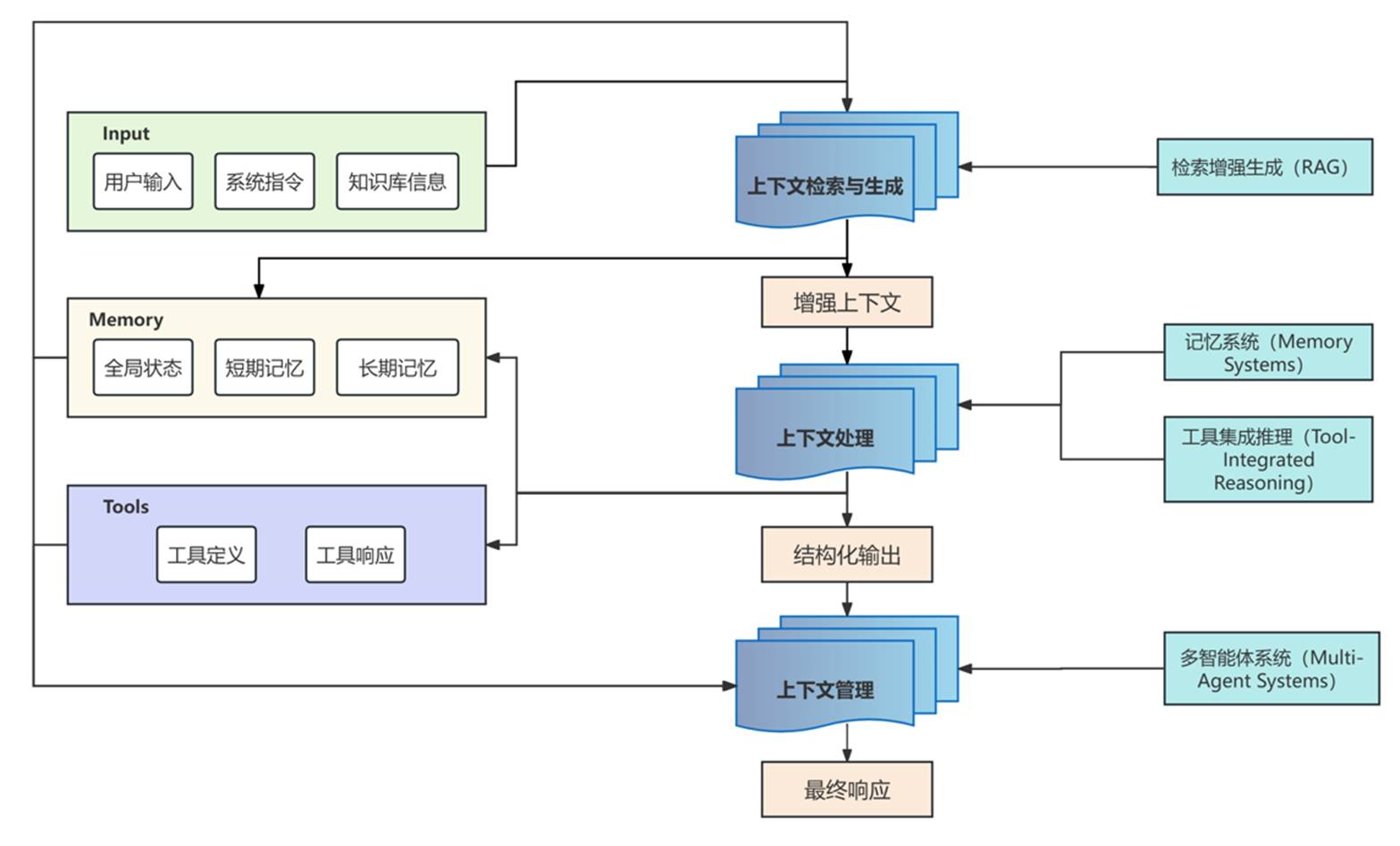
以某些编程agent为例,当你输入一个指令(比如“修复登录逻辑的 bug”)时,它背后的一套可能的“上下文管道”会开始工作:
- 意图识别:先判断你要动哪些代码
- 相关性扫描:构造文件树信息,符号分析等
- 动态扩充:它可能会执行一个grep命令来搜索关键词,读相关内容,如果上下文太长,它会使用一次语义标签来分割内容(如xml:
, , ),这有助于模型区分信息来源。 - token预算管理:确保所有抓取的信息加起来不会超过模型处理的上限,并且预留足够的token生成回答
为什么这被称为“工程”? 因为它涉及非常复杂的算法和启发式策略:
- 分层检索: 决定什么时候该用关键词检索(BM25),什么时候该用语义检索(Vector)。
- 重排序(Reranking): 从检索出的 50 个片段中,选出最有用的 5 个。
- 缓存策略(Prompt Caching): 比如 Claude 的 Prompt Caching 功能。工程上需要设计如何让 Context 的前 80% 保持不变,以降低成本和延迟。
- 自适应截断: 根据任务类型(写代码 vs 解释代码)动态调整保留多少背景信息。